REX d'un e-commerce : 9e Store
Publié le
21 juin 2019
Contexte du projet
Média-Participations est un groupe de presse et d'édition, notamment spécialisé dans la bande dessinée après le rachat de célèbres maisons d'éditions telles que Dargaud, Dupuis, Le Lombard, Kana et bien d'autres. En juin 2018 est lancé un projet de site e-commerce grand public faisant office de boutique centrale de tout ce que peut proposer Média-Participations : bande dessinée, comics, manga, vidéos, figurines et merchandising.
#Happy après trois jours de #SprintZero pour un #ecommerce du tonnerre autour de la #BD - avec #MediaParticipations et la #KNPTeam ! pic.twitter.com/T9yTRDMzK1
— KNP Labs (@KNPLabs) June 14, 2018
C'est donc à KNP Labs qu'est revenu ce projet de grande envergure pour le groupe : 9e store !
Choix techniques et architecture
Le choix de la stack technique reste classique, le besoin l'étant tout autant. Nous sommes donc partis sur une application PHP 7.2 avec Symfony 4 (from scratch avec Flex) le tout servi par Nginx avec PHP-FPM, une base de données MySQL, un serveur d'indexation ElasticSearch ainsi qu'une base de données MongoDB. Pour le front, le HTML est généré par le serveur avec Twig, stylé avec SASS, dynamisé avec ES6, le tout packagé par WebPack. L'ensemble de ces services ont été containerisés avec Docker/Docker Compose, qui nous permet d'avoir un environnement iso en dev, préproduction et production.
Chez KNP Labs, nous utilisons l'approche BDD (Behavior Driven Development) qui consiste à décrire le comportement des classes avec des spécifications (faisant office de tests unitaires) avant leur implémentation. Nous utilisons l'outil phpspec pour cela. Les tests d'intégration sont assurés par funkspec. Quant aux tests d'acceptation (fonctionnels), ils sont délégués à Behat avec un driver Chrome headless.
Nous avons choisi d'orienter notre codebase en suivant les principes du DDD (Domain Driven Design) et de la Clean Architecture, qui permet de découpler entièrement le code dit «métier» correspondant au besoin du client du code dit «infrastructurel» à savoir les frameworks/librairies ainsi que le code qui fait le lien entre les deux. Les répartitions des classes PHP s'articulent autour de cette structure de répertoire :
src/
| Domain/
| | Model/
| | | Article.php
| | | Order.php
| | | Order/
| | | | Item.php
| | | ...
| | Task/
| | | Cart/
| | | | AddAnArticle.php
| | | | ...
| | | Order/
| | | | CheckoutCurrentOrder.php
| | | | ...
| | ...
| Application/
| Symfony/
| Doctrine/
| Elasticsearch/
| Twig/
| ...
Le répertoire Domain contient l'essentiel du code métier et des règles de gestion correspondant aux besoins du projet. Il est écrit en PHP pur, indépendant de tout vendor (à l'exception de quelques librairies utilitaires comme Assert ou UUID). Le modèle est non anémique et fait fortement usage de Value-Objects pour une plus grande expressivité. Tous les cas d'utilisation de l'appli sont encapsulés dans des Tasks (Domain\Task\), une simple classe possédant une unique méthode publique __invoke() et qui est injectée dans les différents points d'entrée de l'appli que ce soit HTTP (Controller) ou CLI (Command). Cela isole la fonctionnalité en un composant réutilisable, évite la duplication de code et sépare les responsabilités.
Le répertoire Application contient quant à lui l'implémentation des interfaces du modèle et fait le pont avec les différentes librairies utilisées (Doctrine, ElasticSearch, Twig, etc.)
Ensuite il existe un répertoire pour chaque vendor nécessitant de la configuration et/ou du code spécifique. Dans le répertoire Symfony par exemple vivront les populaires Controller, Command, FormType, etc., Doctrine accueillera le mapping des entités au format YAML et les classes de migrations, Twig concernera les extensions, ainsi de suite. L’intérêt est de découpler entièrement l'application de ses briques d'infrastructure pour qu'elles soient facilement interchangeables et évolutives.
Pourquoi du custom ?
Bien que la problématique du projet soit relativement simple et ait été déjà solutionnée un nombre incalculable de fois auparavant (e-commerce), le Sprint 0 avec le Product Owner a notamment soulevé des besoins très spécifiques et quelques subtilités dans la façon dont il compte gérer son activité. C'est pour ça que n'avons pas retenu de solutions clés-en-main comme Magento ou Sylius. Le temps passé à configurer et adapter ces solutions pour qu'elles collent aux besoins du projet équivaut à peu près à celui de tout développer par nous-mêmes, avec en moins le bénéfice d'avoir à maintenir un code source dont nous sommes entièrement maître.
Notre expérience chez KNP Labs nous amène d'ailleurs à remettre en question l'utilisation systématique des Bundles Symfony qui, pour une grande majorité d'entre eux et malgré leur description attractive, ne solutionnent jamais à 100% les problématiques et doivent être souvent bidouillés à grands coups de marteau. D'autant plus que la séparation domaine/infrastructurel est plus compliquée avec des bundles qui ne respectent l'approche Clean Architecture. Cela réduit la maintenabilité de la codebase et engendre par conséquent une plus forte dette technique.
Intégration des sources de données externes
Média-Participations nous a mis à disposition plusieurs sources de données de leur SI afin de constituer la base de données d'articles. Elles sont morcelées au nombre de 4, ayant chacune leur particularité :
- le WebContent : web service XML (non conventionnel) exposant les données de la BDA (Base Des Albums), système interne classifiant tous leurs albums, séries, figurines, support vidéo, etc,
- l'API Panier : web service SOAP faisant l'interface avec le logisticien (MDS) qui s'occupe de la facturation et logistique. Il est requêté pour récupérer les prix et stock de chaque article et fait l'interface pour l'envoi/suivi des commandes,
- la BDI (Base Des Images) : endpoint HTTP pour récupérer les images et couvertures de chaque article/livre,
- et enfin les Whitelists : fichiers JSON whitelistant les articles pouvant être vendus sur Weshop. Média-Participations n'étant qu'une holding, c'est à la responsabilité de chaque éditeur (Dargaud, Dupuis, Le Lombard, etc.) de définir leur offre d'achat en fournissant chacun un fichier (7 ici)
Ces services, n'étant pas de toute jeunesse pour la plupart, ont vite montré leurs limites dans le processus de mise à jour incrémentale et journalière de notre modèle ; certaines requêtes HTTP sur le WebContent pouvant prendre plus de 40s (oui) ou bien l'absence totale de pagination de l'API Panier nous forçant à réimporter d'un seul tenant les données de plus de 15000 articles du site.  Nous avons donc opté pour une abstraction complète de tous ses services via une base tampon (Buffer) avec MongoDB et alimentée par des workers PHP pour chaque service (appelés ici des Importers) tournant tous les matins. Cette base tampon fait office de cache/proxy des sources externes en agrégeant et normalisant toutes les données utiles pour la plateforme et évolue indépendamment de la base de données (MySQL) du modèle. En ce qui concerne cette dernière, un worker de mise à jour (appelé Updater) s'occupe de piocher dans la base tampon pour alimenter le modèle de façon incrémentale. Une fois la mise à jour du modèle effectué, il est indexé dans ElasticSearch.
Nous avons donc opté pour une abstraction complète de tous ses services via une base tampon (Buffer) avec MongoDB et alimentée par des workers PHP pour chaque service (appelés ici des Importers) tournant tous les matins. Cette base tampon fait office de cache/proxy des sources externes en agrégeant et normalisant toutes les données utiles pour la plateforme et évolue indépendamment de la base de données (MySQL) du modèle. En ce qui concerne cette dernière, un worker de mise à jour (appelé Updater) s'occupe de piocher dans la base tampon pour alimenter le modèle de façon incrémentale. Une fois la mise à jour du modèle effectué, il est indexé dans ElasticSearch.
Data Workflow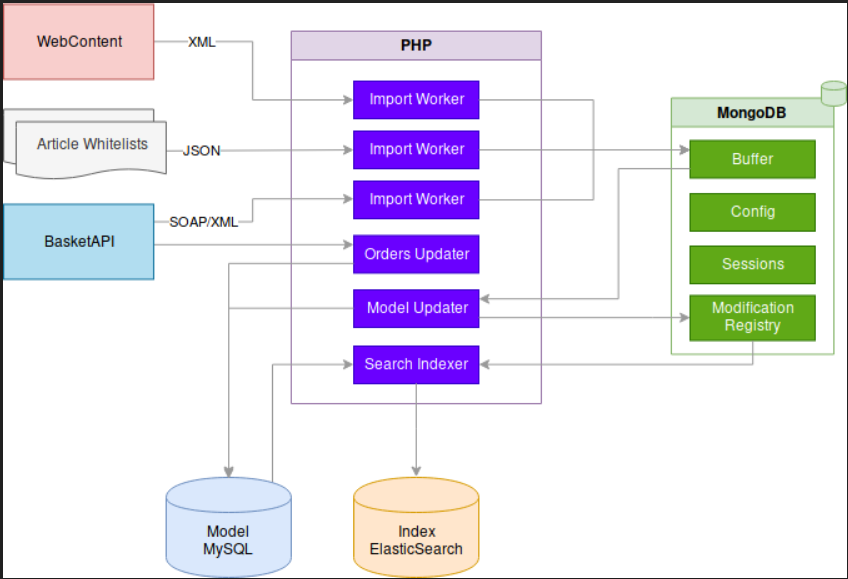
Bonus : Automatic CS-Fixer
Chez KNP Labs, on aime le code propre, bien construit et formaté. Cela évite des écueils courants et facilite la lecture du code par ses pairs. Pour cela, il suffit de définir un code-style unique par langage pour le projet, que chaque développeur doit respecter. PHP-FIG propose déjà des PSRs à ce sujet pour PHP avec notamment la PSR1 et 2 que nous avons suivies et complétées avec d'autres règles. Quand au JS, nous avons choisi le Javascript Style Guide de Airbnb. En bon développeur rusé (ou feignant), une simple configuration de son éditeur de code (conjointement avec .editorconfig) couplé avec un linter fait l'affaire pour automatiquement alerter et/ou corriger les éventuelles transgressions aux règles. Pour peu que chaque développeur joue le jeu, aucun code dit «non conforme» ne devrait être poussé sur le repo Git.
Sur le projet, nous avons poussé le concept plus loin en automatisant globalement le CS-Fixing sur la CI (ici CircleCI). À chaque merge d'une branche de feature sur notre branche dev, un job s'occupe de vérifier la conformité du code aux règles de CS, effectue les corrections si nécessaire, crée une nouvelle branche avec les modifications puis ouvre automatiquement une Pull-Request sur Github.
#!/usr/bin/env bash
set -Eeux -o pipefail
# Lancement des outils de CS-fixing (PHP et ES/SASS)
docker-compose run --rm -u root php composer cs-fix
docker-compose run --rm -u root front yarn cs-fix
# S'il existe un diff (c.a.d qu'il existe au moins un fichier modifié), création d'un fichier .cs_fixed
git diff --quiet || touch .cs_fixed
github_root="${CIRCLE_PROJECT_USERNAME}/${CIRCLE_PROJECT_REPONAME}"
if [[ -f .cs_fixed ]]; then
cs_fixing_branch_name="cs-fixing/${CIRCLE_BRANCH}"
git config --global user.email 'hello@knplabs.com'
git config --global user.name 'Automatic CS Fixer'
# Création d'une nouvelle branche Git
git branch -D "$cs_fixing_branch_name" || true
git checkout -b "$cs_fixing_branch_name"
# Ajout de tous les fichiers modifiés
git add -A
# Commit et push
git commit -am 'Automatic CS fixing'
git push --force-with-lease origin "$cs_fixing_branch_name"
# Notification à Github du statut du CS-fixing
curl -sSi -X POST "https://api.github.com/repos/${github_root}/pulls" -d "{\"title\": \"Automatic CS fixing\", \"head\": \"${cs_fixing_branch_name}\", \"base\": \"${CIRCLE_BRANCH}\"}" -H "Authorization: token ${GITHUB_TOKEN}"
else
curl -X POST "https://api.github.com/repos/${github_root}/statuses/${CIRCLE_SHA1}" -d '{"state": "success", "context": "Automatic CS Fixer", "description": "Coding standards respected!"}' -H "Authorization: token ${GITHUB_TOKEN}"
fi
Avec ce système, peu importe si les développeurs préfèrent les espaces ou les tabulations, le code sera remis au propre dans tous les cas.
Conclusion
Après plus de 35 sprints, 530 pull-requests et 3500 builds sur la CI, Weshop est maintenant un projet dont nous pouvons être fiers. Une architecture découplée et évolutive, propulsée par une approche BDD testée de bout en bout et une relation avec le client full-agile nous a permis de construire un produit robuste et fiable répondant aux besoins d'un client plus que satisfait. La mise en production finale aura lieu en septembre 2019.
Vous avez des questions ? Ou envie de travailler avec nous ? => hello@knplabs.com 
Publié par




Commentaires